Minori sui social: Meta e TikTok si costituiscono nella Class Action; Germania e UE richiamano le piattaforme su età e contenuti
Prosegue la Class Action per la tutela dei minori sui social: Meta (Facebook, Instagram) e TikTok si sono costituite confidando in questioni procedurali per rinviare la discussione
La class action instaurata a Milano dallo Studio A&C su mandato del Movimento Italiano Genitori (MOIGE) e di alcune famiglie i cui figli hanno patito gravi danni a causa delle pratiche dei social di Meta e TikTok – e/o che continuano a subire i seri rischi di pregiudizio legati al funzionamento delle piattaforme – prosegue il suo iter procedurale, muovendo principalmente dalla constatazione che la legge vigente è clamorosamente violata dalle aziende responsabili dei social network.
Le aziende dei gruppi Meta e TikTok si sono costituite nella causa milanese negando l’evidenza e formulando numerosissime eccezioni formali, ottenendo un rinvio della prima udienza di discussione, che è ora fissata per al prossimo 14 maggio.
Nel merito, le società resistenti hanno tentato di dimostrare il presunto rispetto delle norme vigenti, soprattutto attraverso riferimenti a documenti di policy interni ed astratti, scritti dalle aziende stesse o da loro consulenti. Inoltre, come si può notare anche guardando questo breve video che riassume l’azione, pubblicato qui sul nostro sito, le società tentano di affermare di non poter essere ritenute responsabili per le proprie consapevoli scelte imprenditoriali, puntando inoltre il dito su altri soggetti – a partire dai genitori dei minori esposti a rischi e danni sulle piattaforme.
Le difese delle piattaforme sono inconsistenti e non potranno bloccare quello che è un vero tsunami che da tutto il mondo si sta abbattendo su di loro, ora che sono evidenti i disastrosi danni alla salute fisica a mentale che bambini, adolescenti ma anche adulti subiscono dalla frequentazione dei social.
E non mancano le condanne in sede giudiziaria, come quella del Tribunale di Berlino che approfondiamo più avanti (lett. B), o le avvisaglie di ben più pesanti sanzioni da parte della Commissione UE (lett. C).
Ma è tutta la complessiva mobilitazione a livello mondiale che fa impressione, con vari Paesi che osservando i gravissimi rischi e danni allo sviluppo dei minori hanno deciso di approvare ulteriori norme nazionali che proibiscano espressamente l’accesso dei pre-adolescenti ai social. Così, la Spagna di Sanchez (riportiamo il suo recente intervento) ha annunciato una nuova legge che vieterà esplicitamente l’accesso agli under 16, nonché la previsione di una responsabilità legale in capo ai CEO delle big tech per i reati commessi sui social network, descritti come spazi di “dipendenza, abuso, pornografia, manipolazione e violenza“. Analogamente, la Francia sta emanando anch’essa una legge ad hoc che introduce un ulteriore divieto di accesso prima dei 15 anni. Iniziative analoghe si segnalano anche in Grecia, Portogallo, Danimarca ed Austria.
In Australia, la legge su questo tema è entrata in vigore da alcuni mesi ormai.
Un’altra notizia di rilievo sul tema è costituita dalle novità provenienti da Bruxelles (che approfondiamo alla lett. C) relative al procedimento che la Commissione UE ha instaurato contro TikTok già due anni fa, che sta verificando la concretezza dei rischi per i minori collegati alle impostazioni ed al funzionamento dei social.
Analogamente a quanto si osserva nell’ambito di tale azione ai sensi del Regolamento UE Digital Services Act (DSA) anche l’azione di classe instaurata a Milano dallo Studio A&C vuole intervenire sulle impostazioni della piattaforma, di per sé dannose per i giovani utenti. L’azione italiana, in favore degli utenti attivi nella nostra penisola, è volta ad un intervento urgente del Giudice italiano per porre rimedio alla situazione attuale di grave pericolo per i minori, confermata nei giorni scorsi dalle conclusioni preliminari della Commissione.
Nel frattempo, negli Stati Uniti, stanno muovendo i primi passi le numerosissime cause instaurate contro i danni biologici causati ai minori dai social network (dalla dipendenza dalle piattaforme, fino al suicidio), ivi inclusi Meta e TikTok. Le azioni, promosse dai genitori di minori che hanno perso la vita o hanno subito gravi danni biologici, ma anche da ben 40 procuratori degli Stati USAe da distretti scolastici, si fondano anche su copiosa documentazione interna dei due gruppi che attesta la consapevolezza della dipendenza che le piattaforme ingenerano nei minori, a partire dai celebri Facebook Files – documenti allegati peraltro anche alla class action instaurata dallo Studio A&C a Milano.
Il Tribunale di Berlino condanna TikTok per mancata verifica dell’età dei minori:
Il Tribunale regionale di Berlino II, pronunciatosi su una causa proposta dall’Associazione federale dei consumatori (VZBV – Verbraucherzentrale Bundesverband)[1], ha ordinato a TikTok di non utilizzare più i dati personali degli utenti minori di età compresa tra i 13 e i 16 anni non ancora compiuti per finalità di marketing o pubblicità personalizzata.
In Germania, come ovunque in UE per la prassi adottata da tutte le piattaforme, la verifica dell’età dell’utente che si iscrive (in questo caso) a TikTok si basa esclusivamente sulle sole dichiarazioni dall’utente stesso durante il processo di registrazione.
Secondo i Giudici tedeschi tale prassi, con la semplice richiesta della data di nascita al momento della registrazione, costituisce peraltro un chiaro incentivo per i giovani a dichiararsi più grandi per aggirare i limiti di età e le funzioni limitate. Si tratta di una conclusione intuitiva ed in linea con la sostanza della normativa vigente, che è destinata ad essere applicata in tutta Europa, visto il chiaro dettato legislativo che impone invece alle piattaforme di svolgere tutte le verifiche possibili in base all’esperienza ed alla tecnologia disponibile.
Il Tribunale ha ritenuto dunque questa pratica dell’azienda, che favorisce l’accesso indiscriminato di minori nella piattaforma, insufficiente a garantire che i dati personali dei minori di età inferiore ai 16 anni non vengano trattati a fini pubblicitari senza il consenso dei genitori. La vendita di spazi pubblicitari basati sullo studio minuzioso dell’attività degli utenti e delle loro caratteristiche (a partire della loro fascia di età, peraltro) rappresenta infatti la linfa vitale delle piattaforme social, garantendo gran parte dei loro introiti.
Risulta evidente che il minore sotto età che acceda mentendo sulla propria data di nascita fruirà di un’esperienza diversa da quella per lui adeguata, con tutti i rischi che ne conseguono: proprio per evitare tale rischio il Tribunale berlinese ha vietato a TikTok di trattare i dati personali degli utenti registrati di questa fascia d’età senza il consenso dei titolari della responsabilità genitoriale per l’invio di messaggi di marketing e la visualizzazione di pubblicità personalizzate, prevedendo una sanzione fino a 250.000 euro in caso di violazione di tale divieto.
Anche in Italia, per accedere a TikTok (come anche a Instagram e Facebook) basta indicare una data di nascita corrispondente ad almeno 13 anni compiuti.
Questo è contrario alle leggi in vigore nell’Unione Europea e nei suoi Stati membri, come la Germania e l’Italia – a partire dal GDPR (Regolamento generale sulla protezione dei dati) e dai codici privacy nazionali. Il primo prevede all’art. 8 un’età minima di 16 anni per poter accedere ai servizi di social network, consentendo ai legislatori nazionali di fissare un limite minore, non inferiore ai 13 anni, mentre il codice privacy italiano prevede invece il limite minimo di 14 anni, 13 qualora sia presente anche il consenso di entrambi i genitori del minore.
Le conclusioni preliminari della Commissione UE nel quadro del procedimento ai sensi del DSA: design e sistemi additivi, insufficienza della valutazione del rischio
Il 6 febbraio 2026 la Commissione ha divulgato il contenuto delle proprie conclusioni preliminari, nel quadro del procedimento instaurato nel febbraio 2024 nei confronti di TikTok ai sensi del Digital Services Act (Reg. UE 2022/2265), avente ad oggetto la tutela dei minori, la trasparenza della pubblicità, l’accesso ai dati in favore dei ricercatori e la gestione del rischio con riferimento al design additivo ed ai contenuti dannosi.
Secondo la Commissione, TikTok ha violato le norme UE per il suo design che crea dipendenza, il quale include funzionalità come lo scorrimento infinito, la riproduzione automatica dei contenuti, le c.d. notifiche push e il suo sistema di raccomandazione altamente personalizzato.
Il comunicato stampa della Commissione pone l’accento sull’inadeguatezza della valutazione del rischio compiuta dall’azienda sui propri sistemi, evocando altresì i risultati della ricerca scientifica, secondo cui il funzionamento della piattaforma (che rischia di “mettere il cervello in modalità pilota automatico”) può indurre comportamenti compulsivi e a ridurre l’autocontrollo.
TikTok avrebbe inoltre ignorato importanti indicatori dell’uso compulsivo dell’app, come il tempo speso sull’app dai minori anche durante la notte, l’inefficacia degli strumenti di gestione del tempo e di controllo parentale.
La Commissione ritiene che TikTok debba modificare la struttura di base del suo servizio, attraverso la disabilitazione delle principali caratteristiche che creano dipendenza, a partire dallo scorrimento infinito dei contenuti (infinite scrolling), ponendo in essere effettive modalità di interruzione dell’uso dell’app e adattando il suo sistema di raccomandazione.
Annotiamo che l’azione inibitoria di classe promossa dal nostro Studio per il Moige e le Famiglie avanza proprio questa richiesta: la modifica del design delle piattaforme per limitarne il potere di condizionamento a danno dei minori e dei più fragili.
Se l’azienda non adempirà all’invito della Commissione di adeguare i propri sistemi alle norme vigenti, rischia una sanzione fino al 6% del suo fatturato annuo …una cifra monstre di circa 8/9 miliardi di euro!
Per ulteriori approfondimenti, è possibile scrivere ai professionisti dello Studio legale A&C all’indirizzo info@ambrosioecommodo.it.
[1] Landgericht Berlin II, Sentenza del 23.12.2025, 15 O 271/23.
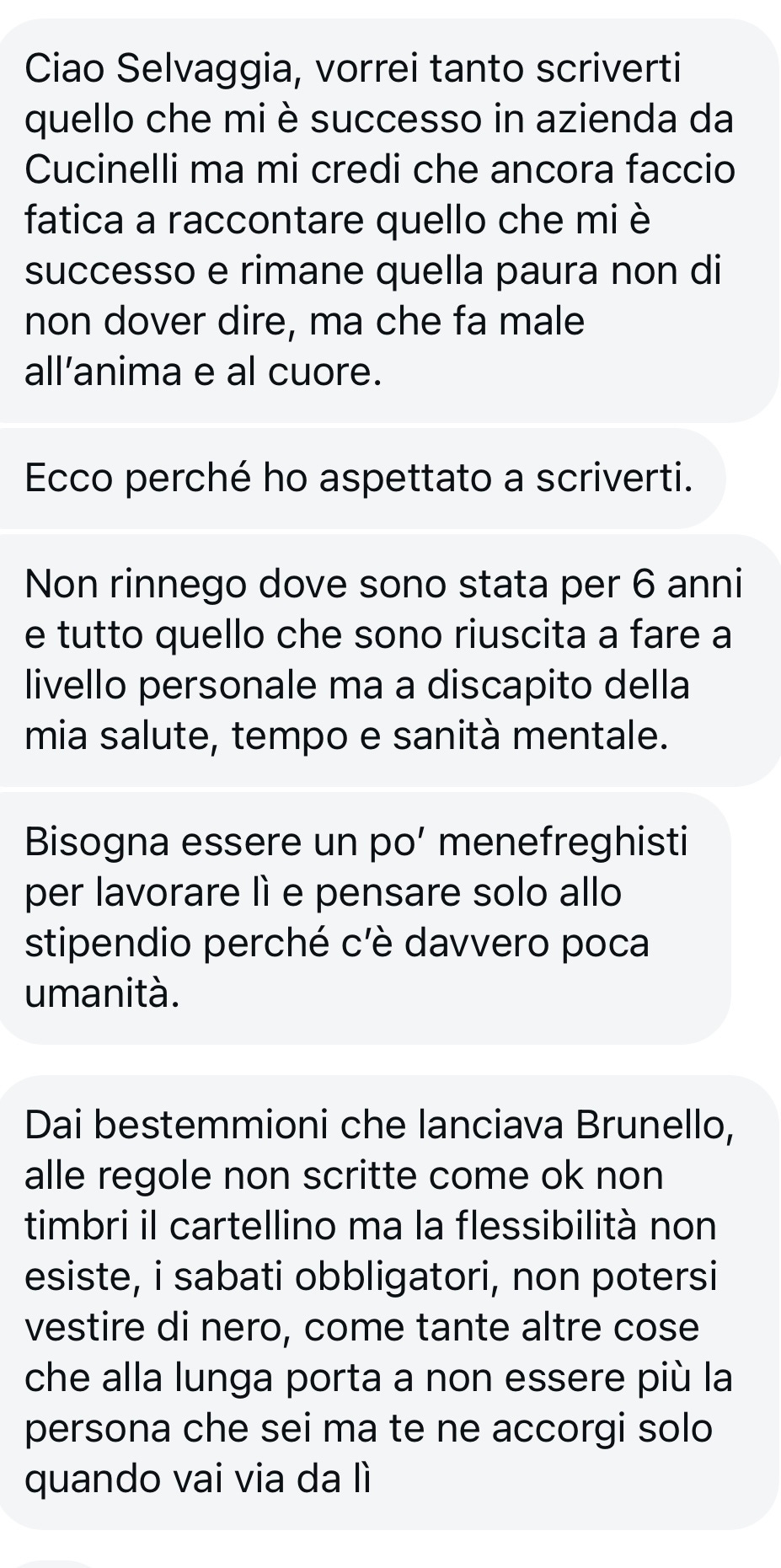
Il lato oscuro di Brunello Cucinelli e della sua azienda
Quando ho scritto qui un ritratto ironico del miliardario “re del cachemire” Brunello Cucinelli e della sua proverbiale megalomania, credevo che la storia fosse autoconclusiva.
E invece, nel giro di poche ore fino ai giorni successivi, mi è arrivato un fiume di messaggi, mail, perfino whatsapp di persone che avevano voglia di raccontarmi la loro esperienza nell’azienda.
Ex dipendenti arrabbiati, traumatizzati o delusi, ma anche dipendenti che hanno bisogno della busta paga e che se potessero, però, scapperebbero via. Sono maglieriste, magazzinieri, dipendenti che lavorano in ufficio, persone che lavorano o hanno lavorato nei negozi, ma anche personaggi che hanno avuto incarichi di rilievo e che hanno sentito l’esigenza di raccontare quanto poco lo storytelling del datore di lavoro virtuoso corrisponda alla realtà. Non solo. Mi hanno scritto persone che lo hanno incrociato in alcuni convegni o a incontri con gli studenti. Una ragazza che lo ha intervistato a un evento di dermatologia mi ha raccontato come lui l’abbia umiliata pubblicamente al punto da farla quasi piangere. E me lo hanno confermato le persone che erano lì, ad assistere. Lei si chiama Antonella Ciocca, e quel giorno doveva intervistare Cucinelli a un convegno di dermatologia a Perugia:
“Cucinelli aveva chiesto di iniziare alle 8,30 e tutti eravamo lì puntuali. Lui è arrivato con un’ora di ritardo, nervoso. A un certo punto ho citato un dato economico relativo a un suo investimento e lui mi ha aggredita dicendo che era sbagliato, che se le sue segretarie fossero state come me sarebbe fallito. Mi ha dato praticamente della cretina, tanto che poi si è girato di schiena e non mi ha più rivolto la parola. Ho provato a difendermi, dall’umiliazione mi si è rotta la voce, stavo per piangere. Quando è finito tutti i dermatologi mi hanno fatto cerchio intorno mortificati, per consolarmi”, mi racconta Ciocca.
Tutto questo sarebbe già significativo, ma quello che accade in azienda (e talvolta nei negozi) è molto più interessante perchè “Brunello Cucinelli” non è un’azienda come tante. Il fondatore ha creato la sua narrazione intorno al concetto di dignità dell’uomo e del lavoratore.
Ha pure fatto costruire un monumento a Solomeo – il borgo umbro che per lui è casa e quartier generale dell’azienda- dedicato proprio a questo. E non perde occasione nelle interviste, sul sito dell’azienda, nel suo film autocelebrativo diretto da Tornatore e persino nel suo discorso al G20 (dove è stato invitato da Mario Draghi) per ribadire il fatto che lui rappresenta una sorta di capitalismo umanistico, per cui il rispetto del lavoratore viene prima del profitto : “Da ragazzo vidi gli occhi lucidi di mio padre umiliato e offeso sul lavoro, e ancora oggi non capisco perché si debba umiliare ed offendere, ma ispirato dal dolore che lessi in quegli occhi decisi che il sogno della mia vita sarebbe stato quello di vivere e lavorare per la dignità morale ed economica dell’essere umano. Volevo un’impresa che facesse sani profitti, ma lo facesse con etica, dignità e morale”, ha detto davanti ai potenti del pianeta.
Sempre a supporto di questa idea grandiosa, Cucinelli ha riqualificato il Borgo di Solomeo (poche centinaia di abitanti in provincia di Perugia), ha comparto il castello e diverse mura, ha fatto costruire o restaurare teatro e biblioteca e ha piazzato lì la sede dell’azienda. Ogni giorno, i suoi dipendenti partono da Perugia e comuni limitrofi per godere del grande privilegio di lavorare per questo imprenditore filosofo e filantropo che racconta quanto sia virtuosa la sua azienda in cui i lavoratori sono circondati da bellezza, non si timbra il cartellino, si fa un’ora e mezzo di pausa pranzo, non si lavora il sabato e la domenica, si lavora dalle 8 alle 17, 30, non si mandano mail o messaggi dopo le 17,30, niente straordinari forzati.
Prima di pubblicare queste testimonianze (ne ho lasciate alcune molto dure fuori) ho provato a contattare lo stesso Cucinelli. Credevo fosse importante per lui sapere cosa raccontano LE PERSONE della loro esperienza in azienda. Cosa pensano i suoi lavoratori- almeno quelli che hanno deciso di parlare- dal momento che li usa così di frequente nella sua narrazione per dare lustro al suo storytelling di imprenditore generoso e illuminato. Pensavo intendesse replicare.
E invece il suo ufficio stampa mi ha fatto sapere che no, non gli interessava approfondire. Peccato. Perchè il visionario garbato avrebbe senz’altro dato spiegazioni interessanti.
Comunque, ho deciso di fare un lavoro accurato almeno quanto la lavorazione del cachemire, e ho suddiviso le testimonianze per macrotemi.
Intanto ho scoperto che il BORGO SOLOMEO è stato soprannominato da abitanti del posto “SOLOMIO” per via della “colonizzazione” di Cucinelli che non solo lo ha reso il suo quartier generale, la sua casa, il suo museo a cielo aperto, ma ha pure piazzato lì un servizio di vigilanza con telecamere e ha l’abitudine di voler eliminare ciò che disturba esteticamente il panorama.
“Ti rifà il paese che è un gioiellino tipo Disney ma se hai una casa “brutta” la compra e la butta giù. Ha anche la vigilanza privata che controlla il paese.
Se lo accetti come Signorotto e lo segui alla corte vivi da Dio”, mi dice una persona del posto. “Ah, un episodio “buffo” … Dal suo magico borgo di Solomeo si vede la zona industriale di Ellera-Corciano che lo infastidisce moltissimo perché deturpa il paesaggio. A dargli fastidio era soprattutto la sede gigantesca del “Brico” che con il suo colore arancione stonava e niente, lui voleva fargli cambiare il colore in verde. Ovviamente non ci è riuscito”.
Il sindacato da Cucinelli non esiste. E questo è bizzarro per una persona che dice di mettere al centro il lavoratore. Nel 2011 la Cgil di Perugia provò a convocare i lavoratori in assemblea, ma come riferì ai tempi il segretario Sgalla “Sappiamo che qualche giorno prima il proprietario dell’azienda, il signor Cucinelli, ha convocato tutti i lavoratori ad un incontro in fabbrica e questi, naturalmente in maniera libera, hanno partecipato e ascoltato quello che il loro datore di lavoro aveva da dire, comprese le sue opinioni sui sindacati, sulla loro utilità e sulla loro contemporaneità. Allora, ci viene il dubbio che la libera opinione di Cucinelli possa aver in qualche modo orientato i suoi dipendenti, o almeno alcuni di essi”. In effetti, sempre secondo gli articoli dell’epoca l’assemblea andò deserta, ma in compenso Cucinelli nello stesso periodo diede un bonus ai dipendenti in busta paga.
Non c’è il sindacato ma a Solomeo c’è il filosofo Giuseppe Moscati che, secondo la leggenda metropolitana del posto, è colui che seleziona gli aforismi celebri che Cucinelli sforna ad ogni incontro pubblico.
Comunque, i macrotemi sono i seguenti:
NIENTE SALUTI
Tanto per cominciare, molti dipendenti raccontano che l’imprenditore non ama essere salutato, una legge non scritta, che viene riferita da colleghi e superiori. Alcuni testimoni: “Lui impone anche il divieto di salutarlo in campagna vendite, io ci ho lavorato una stagione che ero disoccupata e sono scappata”. “Innanzitutto, un fatto esilarante è che quando arrivano Brunello o l’attuale CEO in azienda, non è generalmente “permesso” salutarli, a meno non si abbia direttamente a che fare con loro a livello lavorativo”. “Non ama essere salutato ed è una delle prime cose di cui vieni informata quando vieni assunta. Naturalmente non esiste nulla di scritto a riguardo, ma è così. Tutti lo sanno e, anche lui di riflesso, non saluta nessuno ad eccezione di pochissimi collaboratori che forse reputa alla sua altezza”. “Non lo potevi salutare, capitava spesso di trovarlo in bagno. Perché i bagni erano unisex”.
“Ho lavorato lì tre anni, Brunello in azienda non voleva essere salutato, “non aveva da perdere tempo”, mi sono ritrovata un sacco di volte nei grossi bagni dell’azienda a lavarmi le mani di fianco a lui senza nemmeno essere degnata di un mezzo sorriso”.
Insomma, la dignità del lavoratore è tale che non può neppure dire BUONGIORNO al capo.
LA PAUSA
La famosa PAUSA di un’ora e mezza all’ora di pranzo venduta come una grande concessione di libertà e riposo per il lavoratore non è esattamente un regalo per tutti:“Questa e’ un po’ la loro strategia in ogni cosa: far passare per qualcosa di eccezionale la normalità assoluta. Questo e’ come fanno passare la lunga pausa pranzo di 1 ora e mezza che permette di rientrare a casa (a quelli che abitano a 5 min dall’azienda sperduta nel nulla) e godersi il pranzo. Chi invece abita un po’ più lontano è costretto ad aspettare del tempo infinito a girarsi i pollici nella campagna perugina perchè questo orario non e’ sufficiente per rientrare, ma non è nemmeno possibile ricominciare a lavorare dopo 1 ora o 30 min per finire prima”, mi racconta una dipendente.
NIENTE CARTELLINO E SCARSA FLESSIBILITÀ
C’è poi la storia dell’assenza del cartellino da timbrare, raccontata spesso da Cucinelli come un valore perchè i lavoratori non sono mica numeri da lui. In realtà numerosi dipendenti o ex mi raccontano che non c’è la timbratura del cartellino, ma in compenso ci sono addetti al controllo inflessibili e telecamere. “Non esiste il cartellino per le timbrature e te la raccontano come un “non abbiamo bisogno di controllare i dipendenti”. La verità è che non esistono permessi, guai ad entrare qualche minuto più tardi in ufficio perché il capo ti prende da una parte e ti dice che è il caso che il giorno dopo entri in orario, per lui nessun problema ma ti ha visto un capo ancora più importante dalle telecamere (sentito e visto con le mie orecchie)”.
“Non ci sono cartellini, ma c’e public shaming e terrorismo psicologico se arrivi letteralmente alle 8, 01. Ricordo ancora che ad un collega alle 7, 58 venne inviata una email “sei in ritardo!” dalle “umane risorse” che non vedendolo sull’uscio davano ormai assodato il suo ritardo, effettivo orario di arrivo 8,03. Ho avuto 3 tamponamenti nel periodo in cui ho lavorato li, e tutti per lo stress di arrivare a lavoro con nessun MINUTO di ritardo, forse nemmeno secondo. La flessibilita’ non esiste minimamente in quell’azienda. Lo stile sembra quello del Medioevo con il mezzadro che controlla il contadino”.
“Quanto alla flessibilità, questa sconosciuta. Non hai idea di quante mamme siano costrette a sforzi inauditi per poter accompagnare i bambini a scuola in quanto non concedono la possibilità di modulare il proprio orario. Ultimamente hanno dato la possibilità di entrare alle 8:30, ma comprendi che chi abita a 30 minuti di macchina, pur volendo, non riesce ad organizzarsi in maniera agevole e senza rischiare ogni mattina di fare un incidente per andare al lavoro”.
“Se abiti a Solomeo, altrimenti perdi 1 ora e mezza della tua vita perché lui ci voleva vedere tutti arrivate e andare via insieme (forse troppo difficile gestire orari diversi senza timbrare cartellino). E così, dopo molti anni, ho deciso di licenziarmi rinunciando a un indeterminato nell’unica azienda di moda in Umbria con 2 bambine piccole. Questo andrebbe anche “bene” ma non ti riempire la bocca del benessere dei dipendenti”.
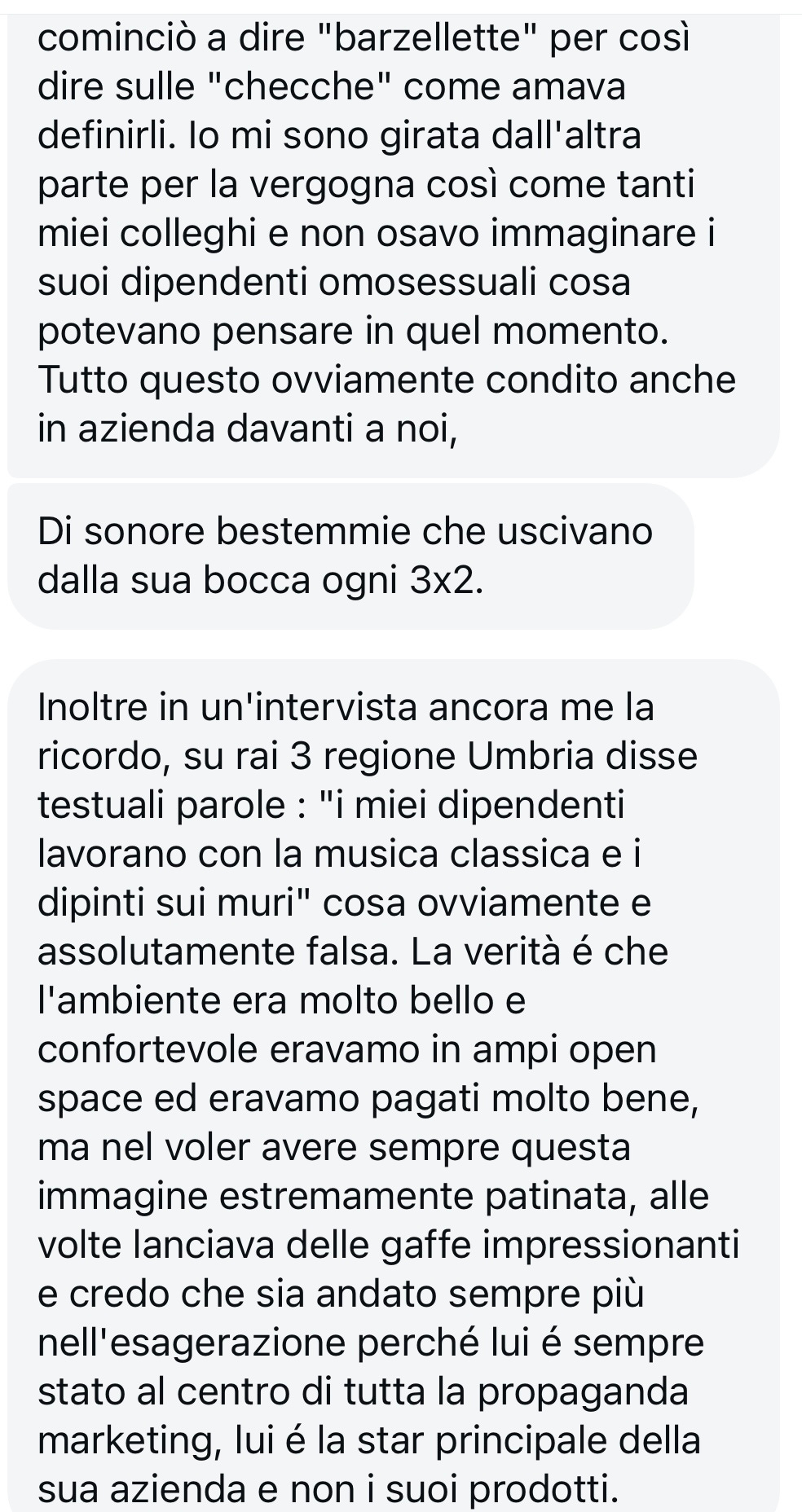
BESTEMMIE E SFURIATE
C’è poi una imponente aneddotica sul carattere rozzo del visionario garbato, che a quanto pare è piuttosto sgarbato: “Alla prima cena di Natale sono rimasta scioccata: non riusciva a mettere insieme due frasi se non con bestemmie trattenute a stento”.
“Ho cenato con lui e con un professore universitario. Sboccato, ha tirato giù non so quante madonne. Non avevo neanche trent’anni, stavo studiando molto tra dottorato e abilitazione forense, dissi che ero stanca. Replicò che avrei dovuto chiedere ai suoi facchini cosa significasse faticare e che magari qualcuno tra quelli mi sarebbe anche piaciuto”.
“Per come bestemmiava e dava degli incapaci ai sarti tutto era fuorché garbato! Detto da uno che ci ha lavorato e di cose in tre anni ne ha viste. Dal mobbing sottile per chi era sovrappeso o a chi semplicemente non indossava i suoi capi in azienda, passando anche alla concezione assurda che i sarti che dovevano avere a che fare con i clienti dovevano essere necessariamente maschi, etero meglio”.
“Il nostro ufficio, prima della nuova disposizione, si trovava proprio di fronte al suo. Inutile dire quante bestemmie possiamo aver udito e quante frasi di cattivo gusto e spesso di stampo misogino rivolte ai suoi più stretti collaboratori”.
“Lui non umilia nessuno”, ma una volta dopo numerosi richiami ad un operaio che si presentava al lavoro con la macchina “sporca”, a sua detta, gli si è presentato con dei soldi (credo venti euro) e gli ha detto che se non poteva permettersi di lavare la macchina i soldi glieli dava lui”.
L’OSSESSIONE PER L’ESTETICA
Cucinelli viene poi dipinto come un maniaco della perfezione estetica, arrivando a creare un clima di paura nell’azienda. I dipendenti devono essere vestiti solo di colori chiari, detesta il nero, controlla perfino le scrivanie e l’estetica delle macchine parcheggiate. “Il terrorismo psicologico che mi hanno fatto pur di non farmi arrivare al colloquio in tailleur nero (ho adorato che sua figlia si e’ poi sposata con guanti di quel colore), il body shaming perpetrato di fronte a tutti verso un povero nuovo arrivato in sovrappeso, facendogli presente che non aveva bisogno di unirsi al resto della comitiva per un rinfresco. Il silenzio, la tensione ed i colori della terra che regnano sovrani nell’ufficio open space a ridosso della brutta copia dei giardini di Versailles”.
“Quando Brunello gira tra gli uffici c’è un clima di terrore assoluto. Una delle prime cose che mi sono state dette è stata di mettere la borsa nell’armadietto perché se lui passa e la trova sulla scrivania o peggio, ci trova il cellulare, sono guai”.
“Un giorno andando in bagno mi hanno ragguagliata dall’ufficio stile dicendomi che avevo ai piedi dei fantasmini neri (fantasmini neri quasi impossibile da vedere su una scarpa) e mi hanno detto che Brunello odiando il nero non voleva mai vedere questo colore sui dipendenti neanche per sbaglio e quindi dovetti toglierli.
“Dovevamo vestirci tutti di beige o bianco (colori che a me per esempio stavano malissimo). Un altro giorno mi dissero che avevo una “camminata” aziendale che andava bene (per fortuna) e rispettava gli standard di Brunello (secondo lui si doveva camminare con velocità, alzando la testa e sempre con dinamicità), poiché secondo Brunello chi non aveva questo tipo di camminata era considerata una persona svogliata e priva di entusiasmo, quindi che avrebbe rallentato il lavoro. Altro aneddoto su come si parcheggiava la macchina sul parcheggio aziendale. Tutti rigorosamente a spina di pesce e se poco poco di qualche centimetro una macchina poteva risultare non proprio a spina di pesce o storta, veniva richiamato immediatamente”.
“I suoi dipendenti sono tutti esauriti. Pretende che al parcheggio nessuno metta l’auto con il muso in posizione di partenza per non dare l’impressione che si voglia andare via il prima possibile”.
“Una volta il suo PA (i suoi PA stavano seduti con le spalle al suo ufficio e lo sguardo rivolto verso il commerciale ) ha chiamato la mia responsabile per dirle di dirmi che avrei dovuto togliermi la pinza (il mollettone per i capelli per intenderci che era medio e marrone, non fucsia) perché non era ok. Sempre noi del commerciale (i più esposti a lui e ai visitatori esterni) non potevamo tenere le bottiglie d’acqua sulla scrivania, per una questione estetica quindi se volevi bere dovevi andare in cucina”.
IL DRESS CODE
Riguardo il dress code dell’aziendale testimonianze non sono tutte perfettamente coincidenti, probabilmente negli anni alcune regole hanno subito variazioni, ma su un elemento convergono: devi vestirti color Cucinelli e se compri qualcosa di Cucinelli è meglio: “Sia le divise per andare in fiera in Germania o durante Pitti erano obbligatorie ed anche vestirsi Cucinelli al lavoro. Le divise ce le davano omaggio per le fiere (2 cambi) tutto il resto dei vestiti (ti parlo all’epoca) ce li compravamo noi al 70% di sconto (da Cucinelli ndr). Ora lo sconto é molto diminuito e varia tra il 30/50%”.
“Nessuno ti costringe ad acquistare abiti Cucinelli, ma è chiara e tangibile la pressione nell’essere sempre abbigliato con capi del brand. Per alcuni dipendenti, non tutti, è prevista una divisa che a causa dei prezzi molto alti consente di acquistare pochi pezzi e, considerando che al lavoro ci si va tutti i giorni, tutto il resto va acquistato di tasca propria… tutto questo se vuoi essere parte del sistema”.
ORARI E STIPENDI
Su orari e stipendi poi, la narrazione portata avanti dall’imprenditore umanista non sembra coincidere esattamente con i racconti di alcuni dipendenti ed ex dipendenti. “Sono una sua dipendente da anni e purtroppo ho un mutuo e ho bisogno del lavoro. Tuttavia vorrei confermarti che purtroppo quasi nulla di quello che si vede è vero. L’ azienda è divisa tra reparti eden e reparti che di dignità dell’ operaio e dell’ impiegato non sanno manco cosa vuol dire. È vero, I’ azienda è bella, pagano regolarissimo. Ma oltre a questo c’ è poco. Straordinari non menzionati, cose che non si possono dire o chiedere perché “non sta bene farlo”. È vero alle 17.30 si esce, ma nessuno menziona i sabati “solidali” in cui devi lavorare perché altri reparti devono lavorare e devi lavorare anche tu, per solidarietà, anche se non c è lavoro. O gli orari di straordinario che hanno fatto fare alle signore, signore che durante i campionari arrivavano a fare in una settimana più di dieci ore di straordinario. È un’azienda come tutte le altre, forse peggio perché almeno le altre hanno la decenza di non parlare”.
“Io ho lavorato lì in un ruolo abbastanza importante. Per essere assunto devi dire di essere d’accorso con la filosofia aziendale. Poi, nonostante il classico contratto a 40h settimanali, ti viene richiesto di lavorare sei sabati mattina l’anno, cosa non scritta né approvata da nessuna parte. Solo per par condicio con gli altri reparti”.
Un’altra ex dipendente mi racconta: “Ad esempio il discorso retribuzione: sembra sempre che regali soldi ai dipendenti, ma in realtà paga per il lavoro svolto in base al ccnl, e ci mancherebbe! Il problema è che in un mondo lavorativo marcio, uno che rispetta il contratto di base si riesce a spacciare addirittura come benefattore. Tra l’altro gli scatti di carriera sono rarissimi.
“Se poi parliamo di diritti dei lavoratori (permessi, malattie dei figli, richiesta di part-time,…).. mi limito a dire che in azienda non esistono i sindacati e una percentuale moooolto alta di donne si licenzia al massimo dopo aver fatto il secondo figlio. lo non ho vissuto questa parte perché me ne sono andata prima di diventare madre, ma per esempio del mio gruppetto di colleghe amiche strette ne lavora ancora lì solo una. Tutte ci siamo licenziate dopo sposate, in pochi anni.
Del nostro ufficio non è rimasto quasi più nessuno, sono tutte nuove. Lui punta molto la sua comunicazione sul benessere in azienda e l’attenzione ai dipendenti, ma la realtà è molto diversa..se si stesse così bene staremmo ancora li, anche perché l’Umbria è piccola, le aziende grandi e valide non sono tante.. Grazie al mio contratto lì ho potuto sposarmi con stabilità lavorativa (me ne sono andata quando ho trovato meglio) e ci hanno concesso facilmente il mutuo, questo devo riconoscerlo, ma non mi ha regalato un centesimo del mio stipendio: ho sempre lavorato a testa bassa e con ritmi serrati, perché i ricchi devono essere accontentati sempre e subito! Quando sono stata assunta ero al settimo cielo, mi sentivo una privilegiata, alla fine la domenica sera quando andavo a dormire mi veniva l’angoscia di rientrare il lunedì.. credo che li dentro io abbia dato il peggio di me in termini di acidità e antipatia, ora sono rinata! Ho sempre preso tra i 1300 e 1.400 circa, sia come apprendista che con l’indeterminato. Con straordinari e trasferte all’estero sono arrivata a 1600, qualche volta a 1800”.
“Sono un ex dipendente che ha speso in quest’azienda molti anni. Ti sono grata per la garanzia relativa all’anonimato. Ci sarebbero tante cose da dire ma tra tutte le le più necessaria credo che ci sia quella relativa agli straordinari. Per anni il reparto delle spedizioni e il magazzino é stato obbligato a lavorare tutti i sabati e ad entrare alle 7 o alle 6 del mattino dal lunedì al venerdì per poi ascoltare le sue castronerie sul tempo da dedicare alla famiglia, sull’assenza degli straordinari fino alla retorica delle 7 ore al giorno spammata su centinaia di social e giornali.
Inoltre non si poteva usufruire di permessi relativi alla malattia dei figli (anche quelli sotto i 3 anni) ma ti chiedevano/obbligavano a scalare le ferie. Credo che se gli si chiede un report sui gg di permesso per malattia dei figli usufruiti dai dipendenti troverà il vuoto siderale”.
“In varie interviste viene citato il fatto che i suoi dipendenti non lavorano il sabato, cosa non vera. Quasi tutti (dalla produzione, al commerciale, al digital al magazzino e così via) lavorano moltissimi sabati all’anno (retribuiti, ma spesso senza una ragione precisa in quanto poi ci si ritrova lì in azienda senza avere realmente del lavoro da svolgere)”.
“Nonostante un contratto a tempo indeterminato ho deciso di licenziarmi quando la mia seconda figlia era ancora piccolissima perché impossibile conciliare vita lavorativa e familiare. Per me che abitavo a più di 50 km dalla sede (quasi 1 ora di macchina in andata e 1 al ritorno), gli orari ASSOLUTAMENTE NON FLESSIBILI non mi hanno permesso di dare la famosa “cura” di cui lui parla tanto alla mia famiglia”.
“Impensabile chiedere si entrare 30 minuti dopo (8.30) magari per accompagnare i bambini all’ asilo o uscire prima riducendo la pausa pranzo (che ricordo era ed è per tutti di 1 ora e mezza, un tempo esagerato quando sei fuori sede). No: gli orari sono fissi, perché “le nostre lavoranti possono tornare a casa a mangiare”. Certo se abiti a Solomeo, altrimenti perdi 1 ora e mezza della tua vita perché lui ci voleva vedere tutti arrivate e andare via insieme (forse troppo difficile gestire orari diversi senza timbrare cartellino). E così, dopo molti anni, ho deciso di licenziarmi rinunciando a un indeterminato nell unica azienda di moda in Umbria con 2 bambine piccole”.
“Trasferte oltre oceano pagate solo per il tempo di permanenza in showroom (no tempo del volo ad esempio) e soprattutto si lavorava a volte anche 20 giorni di fila perché magari lavoravi una settimana, poi nel weekend si partiva, ai stava fuori una settimana e se si rientrava di lunedì ad esempio il martedì dovevo essere al lavoro (sempre stesso orario ovviamente) lavorare tutto la settimana e spesso in campagna vendita anche il weekend successivo per poi ricominciare”.
“Le famose email non oltre le 5.30 hahahahahah questa devo dire che è una delle cose che mi fa più ridere. Forse lui non riceverà email dopo le 5.30. Io mi sono ritrovata lavorare centinata di volte nei negozi di Europa in piena notte, per fare allestimento, e al mio ritorno non è mai esistito prendersi un giorno di riposo (obbligatorio per legge) nonostante lavorassi nei weekend o senza mai uno stop per oltre una settimana. Uguale per tutti i miei colleghi. Tutti gli anni andavamo alla fiera di Dusseldorf, dove eravamo tutti costretti a stare in showroom intere giornate senza fare assolutamente niente e senza sapere quando potevamo uscire. Brunello ci voleva lì tutti ben vestiti educati e sorridenti. Solo la sera quando anche Brunello andava via o arrivava il permesso dall’alto, finalmente potevamo tornare in albergo dopo un intera giornata a girare le grucce”.
CLIMA TOSSICO
Molti lamentano una sensazione di clima ostile, competitivo.
“Lavorare con Brunello è stato un incubo travestito da sogno. Una sudditanza travestita da contratto dipendente. Felice di esserne uscita”.
“Ho vissuto un esperienza molto brutta in azienda. Ho avuto un burn out e mi sono licenziata, a causa dell’ambiente molto freddo e competitivo, sempre colleghi strafottenti, mobbing, e zero empatia. Mi piacerebbe tantissimo leggere le cose che ti stanno scrivendo e avere un contatto un confronto con chi ha vissuto lo stesso appunto. Perché stando lì ti senti una mosca bianca anche solo per il fatto di pensare che“stai male” in posto che tutti lodano e ammirano. Ma io I’ ho sempre chiamata una “gabbia d’oro”, dove si- si guadagna tanto- ma la salute mentale non c’è”.
“Il mal dell‘anima non nasce dal lavoro in sé, né dagli straordinari quando sono riconosciuti. Nasce dalla distanza tra ciò che viene raccontato e ciò che accade per davvero. Mentre sui giornali si parla di un’azienda in cui tutti lavorano fino alle 17:30, la realtà é ben diversa per chi fa inventario o controllo qualità, così per citarne solo alcuni. Basta chiedere a loro. Si parla di dignità dell’uomo attraverso il lavoro, ma poi si ricorre sistematicamente a contratti a termine, tramite agenzie e/o tirocini under 30 per persone già qualificate che potrebbero legittimamente aspirare ad un contratto stabile. A questo si aggiunge un altro elemento significativo, ossia I’ assenza totale di una rappresentanza sindacale, non per caso ma per scelta. In un contesto del genere i dipendenti finiscono per essere trattati come pedine, spostati da un reparto all’ altro non sulla base delle competenze, ma di logiche opache e relazionali”.
“È una gabbia dorata. Tutti ne rimangono estasiati, all’apparenza. Non c’è niente che sia fuori posto, tutto perfettamente in palette, dalle persone, tutte perfettamente abbinate e curate come se andassero ad un matrimonio ai cuscini che trovi nei divanetti. Ma basta davvero poco per accorgersi che ci sono dinamiche al limite della tossicità. Ogni qualvolta si chiede una spiegazione, la risposta è sempre la stessa “si è sempre fatto così”. Questo spiega anche l’altissimo turnover che ha caratterizzato questi ultimi anni”.
“Mi ricordo quando stavo cercando un appartamento per trasferirmi lì a Perugia, la padrona di casa mi guardò e mi disse “sei proprio il genere di ragazza che può lavorare da Cucinelli”, dopo ho capito a cosa si riferiva. Li è come se volessero un certo tipo di persona, acqua e sapone, carina, educata.. e alla fine è come se tu diventassi un soldatino uguale a tutti, è come se ti plasmassero”.
DIPENDENTI COME CAMERIERE
Alcune donne (SOLO DONNE) che lavoravano o lavorano ancora in azienda raccontano di aver dovuto preparare alcuni pasti o il caffè a Cucinelli e ospiti, come fossero state cameriere:
“Un’altra cosa assurda che solo noi donne dovevamo fare a turni era portargli la merenda e a richiesta il caffè. Qualsiasi cosa urgente si stesse facendo, quando il telefono squillava dovevi subito preparare vassoio con mezza fetta di pane e prosciutto su un tovagliolo rosso e portarla al suo segretario, uomo, che la dava a lui. Il segretario non la preparava da solo. E se c’erano ospiti occuparti anche di loro (caffè etc), in pratica le cameriere”.
“Una chicca che merita attenzione è il suo caffè: esiste un file in cui viene spiegato per filo per segno come deve essergli portato il il caffè. La posizione della tazzina, dello zucchero, del cucchiaino… come se fossimo a “cortesie per gli ospiti”. Non sto a specificare il fatto che il caffè viene portato solo dalle donne”.
“Noi ragazze del commerciale avevamo un file in cui ci era assegnato un giorno in cui saremmo state di “turno” In quel giorno, la mattina avremmo dovuto preparare la colazione per Brunello da lasciare nel suo ufficio prima che lui arrivasse. Chi era lì da più tempo di me mi aveva istruito su come disporre il tovagliolo, il panino …
E poi per il resto della giornata rimanevamo a disposizione per servire caffè acqua in caso ci fossero meeting in azienda (mentre ovviamente dovevamo continuare a svolgere il nostro lavoro)”.
Insomma, racconti che fanno pensare più al Megadirettore Galattico di Fantozzi che al capitalista umanista per cui i lavoratori non sono risorse, ma persone portatrici di talento e dignità.
E a proposito di megadirettore, una dipendente racconta: “Ad ottobre 2024 ha ricevuto il premio “WWD John B. Fairchild Honor” in Usa e al suo ritorno in Italia ha piazzato un palco ed un tappeto nel mezzo della fabbrica. É entrato con musica e applausi da parte dei dipendenti percorrendo il tappeto. Poi ha fatto un discorso nel suo solito stile”. Per la cronaca è stato premiato “per aver unito lusso e artigianalità del Made in Italy con una visione etica dell’impresa”.
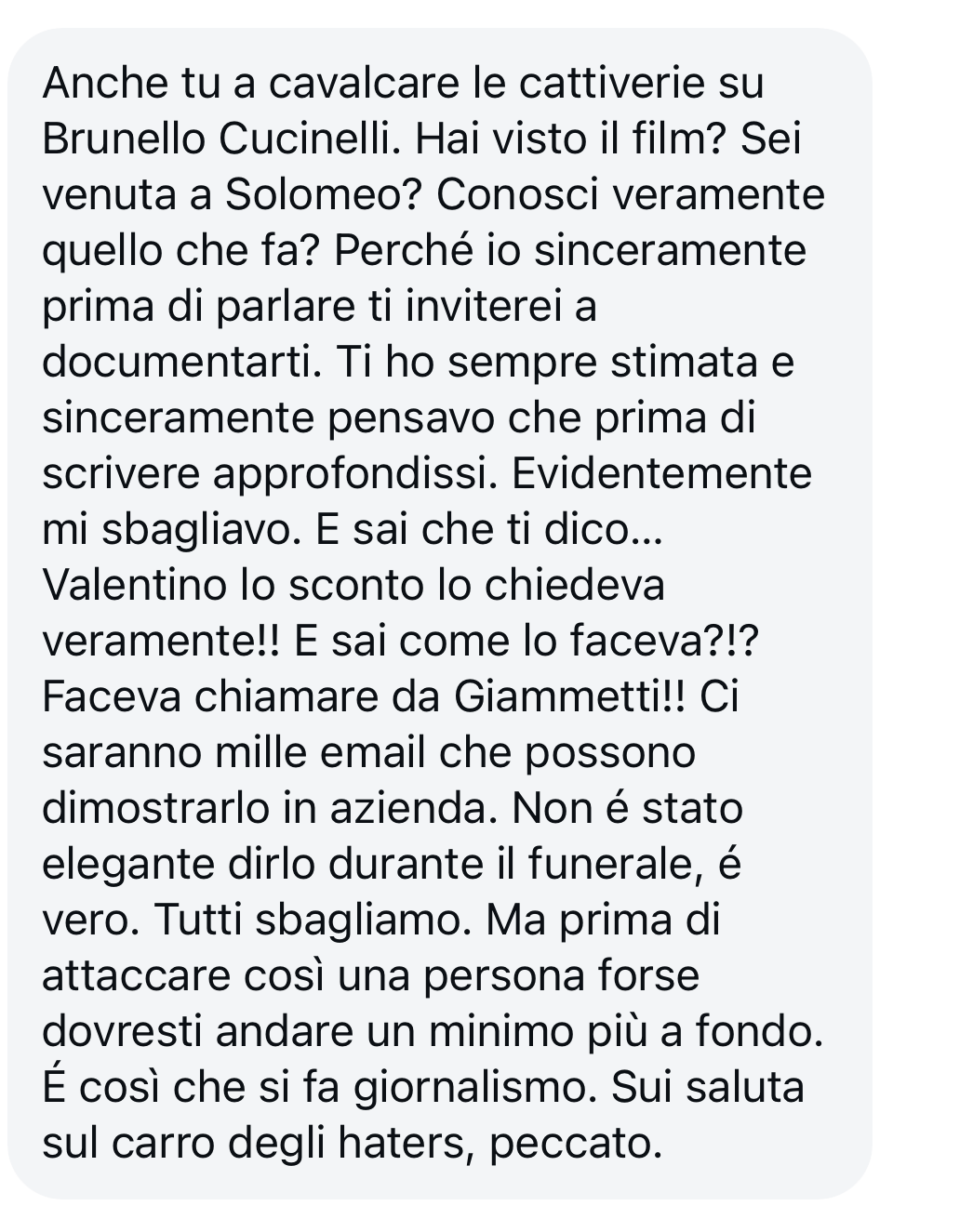
Mi scrive invece una ragazza, S. T., che a quanto pare lavora nella comunicazione di Cucinelli: “Anche tu a cavalcare le cattiverie su Brunello Cucinelli. Hai visto il film? Sei venuta a Solomeo? Conosci veramente quello che fa? Perché io sinceramente prima di parlare ti inviterei a documentarti. Valentino lo sconto lo chiedeva veramente!! E sai come lo faceva?!? Faceva chiamare da Giammetti!! Ci saranno mille email che possono dimostrarlo in azienda. Non é stato elegante dirlo durante il funerale, é vero. Tutti sbagliamo. Ma prima di attaccare così una persona forse dovresti andare un minimo più a fondo”.
Ma a parte questo messaggio un po’ sgangherato il cui contenuto non è verificabile visto il mutismo di Cucinelli e del suo ufficio stampa, non ho ricevuto praticamente altro in difesa dell’azienda o di Cucinelli. Un ex dipendente che aveva un ruolo piuttosto importante, in parziale difesa di Cucinelli, afferma che la responsabilità di ciò che accade in azienda è anche di alcuni amministratori, ma conferma ogni singolo racconto e tutte le criticità che mi sono state segnalate, aggiungendone altre (secondo lui la narrazione dorata del rispetto di orari lavorativi è falsata dal non includere ciò che accade nei negozi Cucinelli, per esempio).
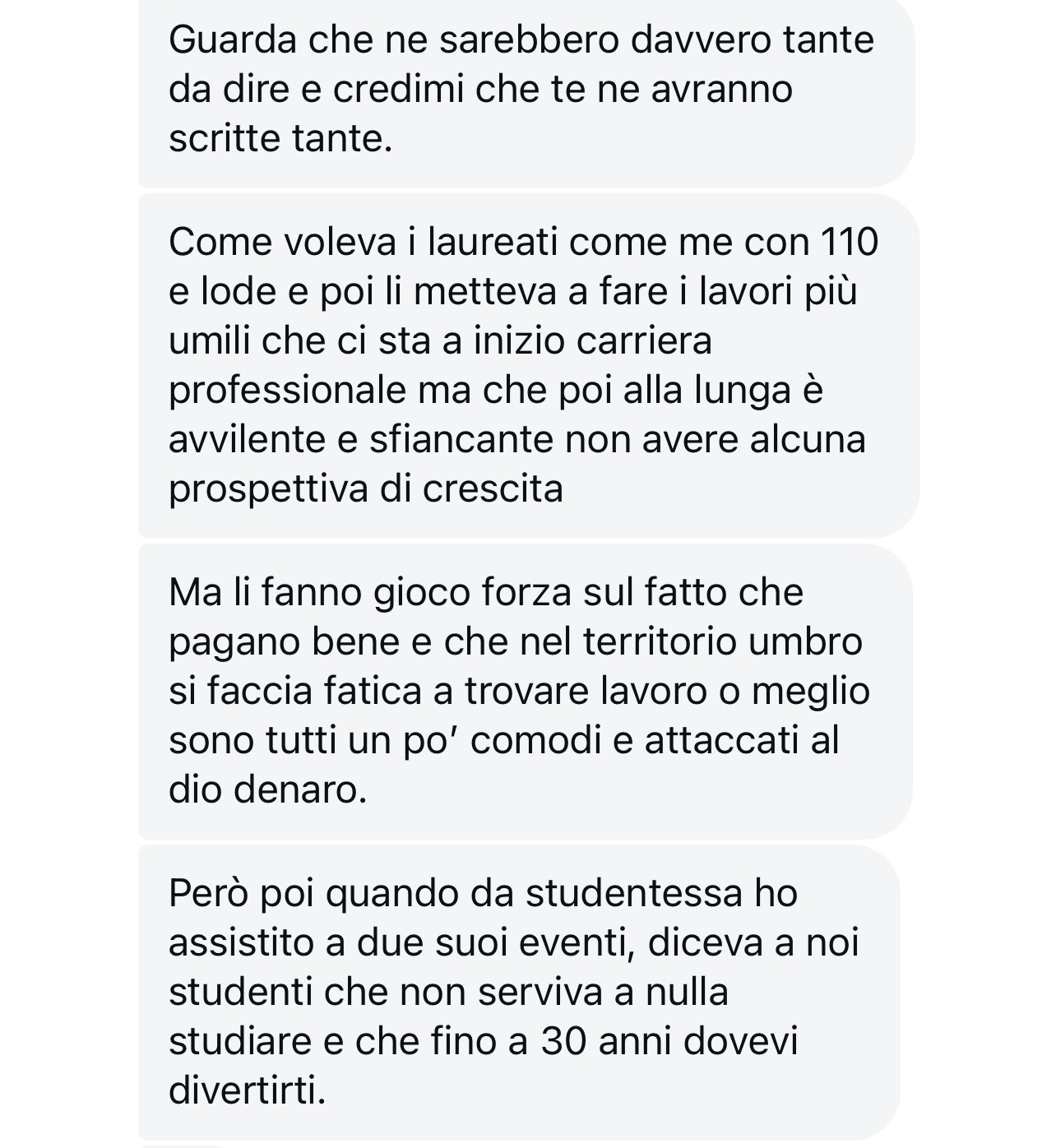
LA SVALUTAZIONE DELLO STUDIO
Un’altra cosa sconcertante è che molti mi hanno riferito quanto Cucinelli svaluti l’importanza dello studio, e in effetti ha rilasciato dichiarazioni in tal senso anche pubblicamente . “Alle lauree triennali di Perugia durante la prolusione disse agli studenti che avevano buttato via tre anni di vita. Che la vita vera si impara al bar, che lui è arrivato dove è arrivato grazie al mondo del bar non certo grazie alla studio”, mi dice un testimone. “Lui non incoraggia gli studi, anzi. Basta guardare il consiglio di amministrazione, i laureati sono pochi. Non lo sono neppure le sue figlie”, mi dice una persona che ha lavorato a stretto contatto con Cucinelli.
Detto ciò, come ho premesso, ho chiesto di potermi confrontare con l’azienda ma ai numeri dell’ufficio stampa milanese non rispondeva nessuno. A quello di Solomeo mi è stato risposto che al momento non rispondeva nessuno all’interno apposito. Poi sono stata contatta dall’ufficio stampa a cui ho spiegato su cosa vertesse l’articolo. Alla fine, molte ore dopo, mi è stato inviato il seguente messaggio: “Gentile Selvaggia Lucarelli, da parte nostra non c’è volontà di approfondire ulteriormente. Grazie e buon lavoro”.
Il messaggio mi è arrivato alle 19,30. Quindi abbiamo la prova: chi lavora per Cucinelli non stacca alle 17,30.
Se lo mangiava Pippo Baudo, poteva mangiarlo chiunque: la rivoluzione a tavola
Siciliano fino al midollo, Pippo Baudo – uno dei quattro moschettieri della televisione nostrana, con Mike Buongiorno, Corrado Mantoni ed Enzo Tortora – non ha mai fatto mistero della sua anima nazional popolare. Entrava nelle case degli italiani con garbo ed ironia, cultura mai esibita e l’immagine rassicurante della persona per bene che tanto piace alle famiglie.
Al conduttore più amato dagli italiani, scomparso l’estate scorsa all’età di 89 anni, viene dedicato quest’anno il Festival di Sanremo, a lui che per tante edizioni ha condotto con il consueto stile che guardava a genitori e nonni ma che sapeva tendere una mano anche a figli e a nipoti (nella foto di apertura Baudo con i vincitori del Festival di Sanremo del 1968: Roberto Carlos e Sergio Endrigo).
Ben più attuale di quanto si era soliti pensare era un esempio di misura ed eleganza, cui si tributava grande autorevolezza, fiducia e familiarità, foss’anche per l’essere stato per quasi 6 decenni una presenza fissa nel sabato sera, nelle domeniche pomeriggio, e nelle lunghe maratone festivaliere.
Un «grande professionista» della tv, influencer ante litteram che se da una parte celebrava con nostalgia la caponata della mamma, dall’altra riusciva a orientare gli acquisti facendosi portavoce di nuovi prodotti che entravano nelle abitudini degli italiani pronti a cambiare stile di vita.
I consigli per gli acquisti di Pippo Baudo
L’Italia che imparava a riconoscere i marchi, cominciava a sostituire i nomi comuni dei prodotti con i nomi propri delle aziende che li producevano e in questa rivoluzione seguiva i suoi consigli per gli acquisti. Dai tempi di Carosello a quelli più recenti degli spot pubblicitari, passando per le sponsorizzazioni dei programmi, Pippo Baudo suggeriva, raccontava, certe volte interpretava pure personaggi che a loro volta diventavano familiari e affidabili.
Ai tempi in cui le pubblicità si chiamavano ancora réclame e non spot, spesso avevano un titolo ed erano sceneggiate da autori di rango (come per esempio Enrico Vaime e Marcello Marchesi) Pippo Baudo normalizzava i prodotti industriali contribuendo all’evoluzione della società: Simmenthal, Motta e via ad andare.
Piaccia o no, negli anni ’60-’70 l’industria alimentare ha impresso un cambiamento nelle abitudini degli italiani e soprattutto delle italiane, accompagnando l’emancipazione femminile e favorendone l’accesso al lavoro, così la carne in scatola poteva risolvere un pranzo in pochi minuti, lo stesso per i biscotti e i dolci che sostituirono man mano quelli casalinghi… e se li mangiava anche il Pippo nazionale poteva mangiarla chiunque. E così anche per i surgelati: Althea divenne un nome noto quando, sul finire degli anni ’70, Baudo prestò la sua notorietà per presentare un disco di canzoni regionali legate a piatti tipici: Ricette in musica (stesso titolo di un programma che presentava su Rai1) era sponsorizzato dal marchio di surgelati.
I brand cominciavano a entrare nei programmi televisivi con siparietti più o meno gustosi, cui Baudo si prestava a partecipare, lasciando che i prodotti si legassero a lui e alla sua credibilità per i milioni di spettatori che lo seguivano. Ci sono stati bibite (Tomarchio Naturà), supermercati (Sma), e poi il caffè Kimbo, che grazie all’effetto Baudo alla fine del secolo scorso conquistò fette di mercato sempre più grandi, e successivamente l’acqua Santa Croce e ancora caffè, stavolta Palombini.
Tutti prodotti di uso e consumo quotidiano, niente che fosse legato a momenti eccezionali, perché Baudo era famiglia, era la quotidianità, era confort. In piena coerenza con le due uscite private, con le interviste, con le (poche) paparazzate che non lo vedevano mai irraggiungibile ma sempre uno di noi: la caponata di mamma, il vino sfuso, gli spiedini di pesce e il fritto di pesce, roba normale, che ordinerebbe chiunque.
Caporalato, controllo giudiziario per Foodinho srl: «Glovo sfrutta 40.000 ciclofattorini pagandoli 2,50 euro a consegna»
«Faccio il rider a partita Iva per Glovo, uso una bicicletta elettrica che ho acquistato io, ricevo in media 2 euro e 50 centesimi a consegna, con incrementi legati alla distanza o ai fine settimana, circa 10/15 consegne al giorno con punte anche di 20/25 percorrendo tra i 50 e 60 km., rimango collegato all’app per circa dodici ore al giorno generalmente dalle 10 alle 22, sono costantemente geolocalizzato con il Gps, se sono in ritardo Glovo mi chiama per sapere perché sono fermo o perché non sto consegnando: se potessi lascerei questo lavoro ma non ho ancora il permesso di soggiorno e non riesco a trovare un altro lavoro, pago 300 euro al mese per un posto letto nella stanza dove vivo con altre tre persone a 35 km. da Milano, spendo 200 euro al mese per prendere il treno, mando 300 euro al mese a mia madre in Pakistan». Decine di testimonianze così. E oggi Foodinho srl, la società che gestisce la piattaforma Glovo di consegna a domicilio di cibo, é stata messa in «controllo giudiziario» con procedura d’urgenza dalla Procura di Milano, secondo la quale «sfrutta la manodopera» (40.000 ciclofattorini in Italia e 2.000 solo nell’area di Milano) perché, «approfittando dello stato di bisogno dei riders» prevalentemente stranieri, li paga «fino all’81% meno della contrattazione collettiva e fino al 76% meno della soglia di povertà», parametrata (attorno ai 1.245 euro al mese per 13 mensilità) su indicatori come il reddito di cittadinanza, la cassa integrazione guadagni, la nuova assicurazione sociale per l’impiego, e l’indice di povertà Istat: retribuzione contrastante con l’articolo 36 della Costituzione, cioè «sicuramente non proporzionata né alla qualità né alla quantità del lavoro» e non in grado di «garantire una esistenza libera e dignitosa».
Affiancamento in azienda
Il controllo giudiziario, cioè la nomina di un amministratore giudiziario che per conto dei magistrati non sostituisce ma affianca gli organi gestori dell’azienda, viene disposto quando c’è da interrompere una situazione di ritenuta illegalità ma l’interruzione dell’attività imprenditoriale potrebbe comportare ripercussioni negative sui livelli occupazionali o compromettere il valore economico del gruppo. Sarà dunque ora l’amministratore giudiziario Andrea Adriano Romanò a dover bonificare il rispettodelle regole violate secondo la Procura, e regolarizzare i lavoratori impiegati sinora da Foodinho srl con «una politica di impresa che rinnega esplicitamente le esigenze di rispetto della legalità» teoricamente cristallizzate «nel modello organizzativo», invece «inidoneo a garantire che si verifichino situazioni di pesante sfruttamento lavorativo riconducibili alla fattispecie penale dell’articolo 603» (caporalato): «Situazioni anzi deliberatamente ricercate ed attuate», per le quali la società vede indagato come persona fisica l’amministratore unico spagnolo Oscar Pierre Miquel.
L’eterodirezione algoritmica
In Foodinho srl – società italiana da 255 milioni di fatturato annuo con clienti principali come Mcdonald’s, Burger King o Poke House, controllata da una società spagnola che fa capo a un gruppo tedesco riconducibile a fondi di investimento statunitensi, e ora indagata come società in base alla legge 231 del 2001 sulla responsabilità amministrativa degli enti per reati commessi dai vertici nell’interesse aziendale – l’intero ciclo di lavoro è mediato dall’app. L’accesso al lavoro, l’assegnazione dell’incarico, la tracciabilità dell’esecuzione e la contabilizzazione ai fini del compensodipendono dall’infrastruttura digitale: il rider non determina in modo autonomo il processo produttivo, ma si rende disponibile tramite l’app e svolge una sequenza operativa standardizzata, tracciata e valutata dalla piattaforma, che governa l’allocazione del lavoro e incide sulla continuità delle occasioni di guadagno tramite parametri di performance (accettazione, puntualità, disponibilità).
Da 5.000 a 12.000 euro in meno l’anno
L’inchiesta del pm Paolo Storari con i carabinieri del Nucleo Tutela Lavoro aggrega lo studio dell’architettura informatica di Glovo, le testimonianze di decine di ciclofattorini, le sei sentenze dell’ottobre 2023 con cui la Cassazione ha precisato la nozione di «salario minimo costituzionale» in base all’articolo 36 della Costituzione, la circolare ministeriale sui casi di applicazione «rimediale» della disciplina del lavoro subordinato, e le sentenze dei giudici del lavoro sulla eteroorganizzazione algoritmica della prestazione di lavoro subordinata. E su queste basi ritiene di concludere che, per una attività lavorativa con una disponibilità oraria media di 9/10 ore giornaliere per almeno sei giorni la settimana, la maggior parte dei riders riceva un reddito netto annuo sotto soglia di povertà per uno scostamento medio di circa 5.000 euro annui, con casi di scostamenti superiori anche a 12.000 euro annui.
Vita cambiata sinora per 52.000 lavoratori
Il volume potenziale dei lavoratori in gioco – 40.000 – nel caso di Glovo è enorme se solo si considera che sinora, a seguito di analoghe inchieste condotte in Procura a Milano dal pm Storari, 36 società hanno internalizzato 52.470 lavoratori (secondo i dati Inps) prima in balia di societá-serbatoio: esito ben più significativo del pur rilevante incasso per lo Stato, determinato dal fatto che collateralmente le aziende (soprattutto della logistica, della vigilanza privata e della grande distribuzione) abbiano inoltre saldato i propri conti con il Fisco per 1 miliardo e 72 milioni di euro.
Il declino del desiderio di leadership tra i giovani manager
Una delle tradizionali unità di misura del potere di un manager è il numero delle persone alle sue dipendenze nell’organigramma: più ne comandi più conti secondo un vecchio schema gerarchico. Seguendo questo modo di ragionare il concetto di “fare carriera” coinciderebbe con il concetto di diventare capo e di aumentare con il tempo il numero di persone coordinate.
Sebbene sia difficile trovare delle evidenze statistiche che lo dimostrino, dall’osservazione empirica dei percorsi professionali degli ultimi anni sembra emergere un dato: “essere capo” è un desiderio meno sentito di una volta. Non è raro trovarsi di fronte a “vecchi” manager, cresciuti in un contesto culturale in cui l’investitura a leader era un destino glorioso a cui non ci si poteva sottrarre, che scuotono la testa basiti perché il giovane collega non ha accettato un incarico di responsabilità preferendo ripiegare su una dimensione lavorativa più tranquilla o su un progetto professionale più stimolante.
I sociologi del lavoro probabilmente ci potrebbero dire che oggi le nostre esistenze sono meno “lavorocentriche” di un tempo, che ci piace sempre meno essere definiti come persone dal nostro status professionale. Ritengo però esista almeno un altro motivo più concreto che porta molti di noi nelle nostre scelte di carriera a non considerare più come un must l’opportunità di “essere capo”. Si tratta dello spostamento dell’equilibrio “onori-oneri” che la responsabilità manageriale porta con sé.
Guidare delle persone comporta gratificazioni importanti, materiali (stipendi, benefit, ecc.) e soprattutto immateriali (potere, visibilità, considerazione sociale, ecc.). Ovviamente ci sono anche gli oneri. Se nella nostra scala di valori personali gli onori immateriali (lo status del “boss”) contano meno di prima e non sono controbilanciati da una riduzione degli oneri (lo stress quotidiano di garantire risultati gestendo le mille esigenze delle persone alle proprie dipendenze) allora fisiologicamente c’è chi dice “no, grazie, non ne vale la pena”. Questo accade soprattutto quando il ruolo di manager prevede responsabilità non adeguatamente proporzionate al livello di autonomia decisionale e all’effettiva capacità di impattare sul business.
Comandare è meno facile di una volta. L’universo simbolico dell’autorità in azienda ha subito nei decenni lo stesso processo di destrutturazione che abbiamo osservato a proposito dell’autorità in famiglia. Se mio padre poteva impormi le sue decisioni con uno sguardo, per ottenere lo stesso obiettivo nei confronti dei miei figli io devo faticosamente spiegare e persuadere. E se cado nella tentazione di sbraitare ed impormi con la forza perdo autorevolezza e credibilità. Ceteris paribus si può dire lo stesso nelle dinamiche capo-collaboratore sul lavoro. Le aziende sono piene di capi frustrati che si devono impegnare in faticosissime e costosissime negoziazioni per ottenere dai propri collaboratori piccoli sforzi in più, per conseguire i quali magari una volta era sufficiente una mezza battuta ironica. Insomma comandare piace ancora, ma quanta fatica. Per molti il gioco non vale la candela.
Questa tendenza ci dice che un domani avremo problemi di scarsità di manager? Difficile rispondere. Certamente dirigenti e imprenditori devono tenere conto che comandare non è più una leva motivazionale seducente come una volta. Di fronte alla scelta tra un incarico di responsabilità manageriale con tante persone nel team e un incarico senza responsabilità di coordinamento ma con la possibilità di avere un più forte impatto sulla mission aziendale e/o di acquisire competenze di frontiera oggi in tanti sceglierebbero la seconda opzione.
Le aziende inoltre devono offrire strumenti di management ai propri responsabili, in particolare formazione e coaching. Comandare è un’arte sottile e complessa, non è più una mera facoltà (“si fa come dico io e basta”) che si può esercitare senza manuale delle istruzioni.
Più in generale forse dobbiamo riconsiderare il vecchio assioma di radice organizzativa militare per cui il giovane talento e/o l’aziendalista e/o lo stakanovista nella sua progressione di carriera deve necessariamente passare da progressive esperienze di comando. Non è detto che chi lavora bene e con passione debba per forza essere valorizzato o premiato attraverso la leva del “potere sulle persone”.